


LLM架构系列 ---探索文本嵌入模型:从基础到BERT与SBERT实战
本文1W字,探讨了各种用于生成文本向量表示的嵌入模型,包括词袋模型(BoW)、TF-IDF、Word2Vec、GloVe、FastText、ELMO、BERT等等。深入研究了BERT的架构和预训练,介绍了用于高效生成句子嵌入的句子BERT(SBERT),并提供了一个使用
sentence-transformers库的实践示例。有些内容是翻译自 HuggingFace 和一些论文,更多 LLM 架构文章点击查看:LLM 架构专栏
大模型架构专栏文章阅读指南
欢迎加入大模型交流群:加群链接 https://docs.qq.com/doc/DS3VGS0NFVHNRR0Ru#
公众号【柏企阅文】
1. 嵌入模型
嵌入是一种单词表示形式(用数字向量表示),它能让含义相似的单词具有相似的表示。这些向量可以通过各种机器学习算法和大型文本数据集来学习。词嵌入的主要作用之一,是为文本分类和信息检索等下游任务提供输入特征。

在过去十年中,已经提出了几种单词嵌入方法,以下是其中一些。

1.1. 与上下文无关的嵌入
与上下文无关的嵌入重新定义了单词表示,无论上下文如何变化,都会为单词分配唯一的向量。这种方式为每个单词分配不同的向量,而不考虑上下文。像“duck”这样的同音异义词会得到一个向量,在没有上下文提示的情况下,这个向量融合了该词的多种含义 。该方法生成了一个全面的词向量映射,以固定的表示形式捕获单词的多种含义。

与上下文无关的嵌入虽然效率较高,但在对语言进行细致理解时,尤其是处理同音异义词时,会面临挑战。这种范式的转变促使我们更仔细地审视自然语言处理中的权衡问题。
一些常见的基于频率的上下文无关嵌入:
- 词袋模型(Bag of Words):词袋模型会创建一个包含所有句子中最常见单词的词典,然后对句子进行编码。
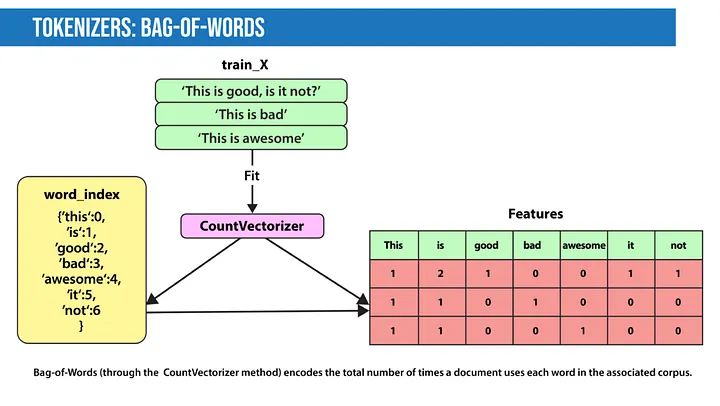
- TF-IDF:TF-IDF是一种从句子中提取特征的简单技术。在Count features中,我们对文档中出现的所有单词/ngram进行计数,而TF-IDF只对重要单词提取特征。怎么做呢?如果考虑语料库中的某个文档,我们会从两个方面考量文档中的任何一个单词:
- 术语频率(Term Frequency):该单词在文档中的重要程度如何?

- 逆向文档频率(Inverse Document Frequency):该术语在整个语料库中的重要程度如何?
- 术语频率(Term Frequency):该单词在文档中的重要程度如何?


一些常见的基于预测的上下文无关嵌入:
- Word2Vec:Word2Vec中的单词嵌入是通过一个两层神经网络学习得到的,在训练过程中,该网络会无意间捕获语言上下文信息。这些嵌入是算法主要目标的副产品,展示了这种方法的高效性。Word2Vec通过两种不同的模型架构提供了灵活性:连续词袋(CBOW)和连续跳元(continuous skip-gram)。
- 连续词袋(CBOW):从周围上下文词的窗口预测当前单词,强调上下文词在预测目标词时的协同作用。
- 连续跳元(continuous skip-gram):使用当前单词预测上下文单词的周围窗口,侧重于目标词在生成上下文词时的预测能力 。Word2Vec的双模型架构在捕获语言细微差别方面具有多功能性,从业者可以根据自然语言处理任务的具体需求,在CBOW和连续跳元之间进行选择。了解这些架构之间的相互作用,有助于在不同场景中更好地应用Word2Vec。


- GloVe(Global Vectors for Word Representation):GloVe的优势在于,在训练过程中,它利用了语料库中聚合的全局单词共现统计信息。生成的表示不仅封装了语义关系,还揭示了单词向量空间中有趣的线性子结构,加深了我们对单词嵌入的理解。
- FastText:与GloVe不同,FastText采用了一种新颖的方法,将每个单词视为由字符n-gram组成。这一独特的特性使FastText不仅能够学习生僻词,还能巧妙地处理词汇表之外的单词。对字符级嵌入的重视,让FastText能够捕捉到形态学上的细微差别,从而更全面地表示词汇。
1.2. 上下文相关的嵌入

上下文相关的方法会根据单词所处的上下文,学习同一单词的不同嵌入。
- 基于RNN
- ELMO(Embeddings from Language Model):基于一个具有字符编码层和两个双向长短期记忆网络(BiLSTM)层的神经语言模型,学习上下文相关的单词表示。
- CoVe(Contextualized Word Vectors):使用一个经过机器翻译训练的注意力序列到序列模型中的深度LSTM编码器,对词向量进行上下文处理。
- 基于Transformer
- BERT(Bidirectional Encoder Representations from Transformers):这是一个基于Transformer的语言表示模型,在大型跨域语料库上进行训练。它应用掩码语言模型来预测序列中随机被掩码的单词,随后进行下一句预测任务,以学习句子之间的关联。
- XLM(Cross-lingual Language Model):这是一个Transformer模型,通过下一个标记预测、类似BERT的掩码语言建模目标和翻译目标进行预训练。
- RoBERTa(Robustly Optimized BERT Pretraining Approach):它基于BERT构建,修改了关键超参数,去除了下一句预训练目标,并使用更大的小批量数据和学习率进行训练。
- ALBERT(A Lite BERT for Self-supervised Learning of Language Representations):它提出了参数缩减技术,以降低内存消耗并提高BERT的训练速度。
2. BERT
BERT(Bidirectional Encoder Representations from Transformers)是谷歌AI开发的自然语言处理领域的强大模型,它重塑了语言模型的格局。接下来深入探讨其预训练方法和双向架构的复杂性。
- 预训练:BERT针对两个无监督任务进行预训练——掩码语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction,NSP)。MLM会随机掩码输入中15%的标记,目标是仅根据上下文预测被掩码单词的原始词汇表ID。除了掩码语言模型,BERT还使用NSP任务联合预训练文本对表示。许多重要的下游任务,如问答(QA)和自然语言推理(NLI),都基于对两个句子之间关系的理解,而这是语言建模无法直接捕捉到的。
- 预训练数据:预训练过程在很大程度上遵循了现有关于语言模型预训练的文献。预训练语料库使用了书籍语料库(8亿字)和英文维基百科(25亿字)。
- 双向:与从左到右的语言模型预训练不同,MLM目标使得表示能够融合左右上下文信息,这让我们可以预训练一个深度双向Transformer。BERT的架构由多个编码器层组成,每个编码器层对输入应用自注意力机制,并将结果传递给下一层。即使是最小的变体BERT BASE,也拥有12个编码器层、一个具有768个隐藏单元的前馈神经网络模块和12个注意力头。

2.1. 输入表示
BERT将由句子或句子对(例如,<问题,答案>)组成的一个标记序列作为输入序列,用于问答任务。
输入序列在输入到模型之前,会使用词汇量为30k的WordPiece Tokenizer进行预处理,它的工作原理是将一个单词拆分成几个子词(Tokens)。
特殊标记包括:
- [CLS]:用作每个序列的第一个标记。在分类任务中,与这个标记对应的最终隐藏状态会被用作聚合序列表示。
- [SEP]:句子对会被打包成一个序列。我们通过两种方式区分句子:一是用特殊标记[SEP]分隔它们;二是为每个标记添加一个学习得到的嵌入,用于指示该标记属于句子A还是句子B。
- [PAD]:用于表示输入句子中的填充(空标记)。模型要求输入的句子长度固定,因此会根据数据集确定最大长度。较短的句子会被填充,较长的句子则会被截断。为了明确区分真实标记和[PAD]标记,我们会使用注意力掩码(attention mask)。
此外,还引入了分段嵌入来指示给定标记属于第一句还是第二句,位置嵌入用于表示标记在句子中的位置。与原始Transformer不同,BERT从绝对序数位置学习位置嵌入,而不是使用三角函数。
对于给定的标记,其输入表示是通过将相应的标记嵌入、段嵌入和位置嵌入相加得到的。
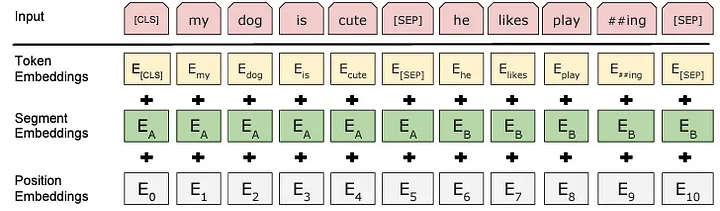

为了获得标记嵌入,在嵌入层会使用嵌入查找表(如上图所示),其中行表示词汇表中所有可能的标记ID(例如30k行),列表示标记嵌入的大小。
2.2. 为什么句子BERT(S-BERT)优于BERT?
到目前为止,一切都进展顺利,但这些Transformer模型在构建句子向量时存在一个问题:Transformer使用的是单词或标记级别的嵌入,而不是句子级别的嵌入。
在句子转换器出现之前,使用BERT计算准确句子相似度的方法是使用跨编码器结构。这意味着我们要将两个句子输入到BERT中,在BERT顶部添加一个分类头,然后用它输出相似度分数。
BERT跨编码器架构由一个BERT模型构成,该模型处理句子A和句子B。两个句子按相同顺序处理,由[SEP]标记分隔。之后是一个前馈神经网络分类器,输出相似度分数。


跨编码器网络确实能产生非常准确的相似度分数(比SBERT更好),但它的扩展性不佳。如果我们想在一个包含10万个句子的小型数据集中进行相似度搜索,就需要完成10万次跨编码器推理计算。
为了对句子进行聚类,我们需要比较10万数据集中的所有句子,这将导致近5亿次比较,这显然是不现实的。
理想情况下,我们需要预先计算可以存储的句子向量,然后在需要时使用。如果这些向量表示效果良好,我们只需要计算它们之间的余弦相似度即可。使用原始BERT(和其他Transformer)时,我们可以通过对BERT输出的所有标记嵌入求平均值来构建句子嵌入(如果输入512个标记,就会输出512个嵌入)。[方法 — 1]
或者,我们可以使用第一个[CLS]标记(一个特定于BERT的标记,其输出嵌入用于分类任务)的输出。[方法 — 2]
使用这两种方法中的任何一种,都能让我们更快地存储和比较句子嵌入,将搜索时间从65小时缩短到大约5秒。然而,这种方法的准确性并不理想,甚至比使用平均GloVe嵌入(2014年开发)还要差。

因此,使用BERT从1万个句子中找到最相似的句子对需要65小时,而使用SBERT,大约5秒就能创建嵌入,并且用大约0.01秒就能通过余弦相似度进行比较。
自SBERT论文发表以来,已经使用与训练原始SBERT类似的概念构建了更多的句子转换器模型。这些模型都在许多相似和不相似的句子对上进行训练。
通过使用诸如softmax损失、多负例排序损失或均方误差边际损失等损失函数,这些模型经过优化,能够为相似的句子生成相似的嵌入,为不相似的句子生成不同的嵌入。
推导独立的句子嵌入是BERT的主要问题之一,为了缓解这一问题,人们开发了SBERT。
3. 句子转换器
我们之前解释了使用BERT进行句子相似度计算的跨编码器架构。SBERT与之类似,但去掉了最后的分类头,并且一次只处理一个句子。然后,SBERT在最终输出层使用均值池化来生成句子嵌入。
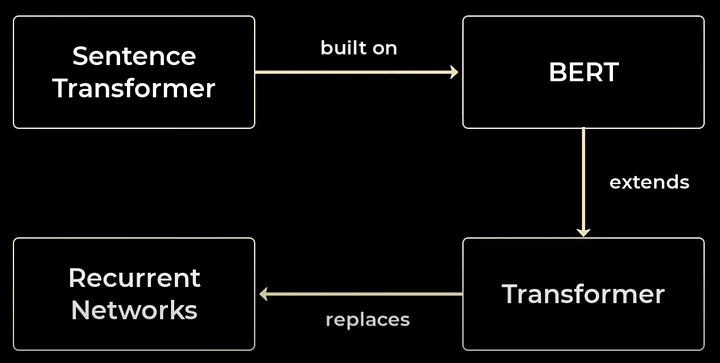
与BERT不同,SBERT使用孪生(siamese)架构在句子对上进行微调。我们可以把它想象成有两个并行的相同BERT,它们共享完全相同的网络权重。

实际上,我们使用的是单个BERT模型。不过,由于在训练过程中我们将句子A和句子B作为一对依次处理,所以更容易把它想象成两个权重绑定的模型。
3.1. Siamese BERT Pre-Training
训练句子转换器有不同的方法,我们将介绍原始SBERT论文中最突出的原始过程,该过程基于softmax损失进行优化。

softmax损失方法使用在斯坦福自然语言推理(SNLI)和多体裁自然语言推理(MNLI)语料库上微调的“Siamese”架构。
SNLI包含57万个句子对,MNLI包含43万个句子对。这两个语料库中的句子对都包含一个前提和一个假设,并且每对句子都被分配以下三个标签之一:
- 0 — 蕴涵,例如前提暗示了假设。
- 1 — 中性,前提和假设都可能为真,但它们不一定相关。
- 2 — 矛盾,前提和假设相互矛盾。
给定这些数据,我们将句子A(假设为前提)输入到孪生BERT A中,将句子B(假设)输入到孪生BERT B中。
孪生BERT输出经过池化的句子嵌入。SBERT论文中给出了三种不同池化方法的结果,分别是均值池化(mean)、最大池化(max)和[CLS]池化。在NLI和STSb数据集上,均值池化方法的表现最佳。
现在有两个句子嵌入,我们将嵌入A称为u,嵌入B称为v。下一步是将u和v连接起来。同样,测试了几种连接方法,表现最好的是(u, v, |u-v|)操作:

|u-v|表示计算两个向量之间的元素差值。除了最初的两个嵌入(u和v),这些结果都被输入到一个具有三个输出的前馈神经网络(FFNN)中。
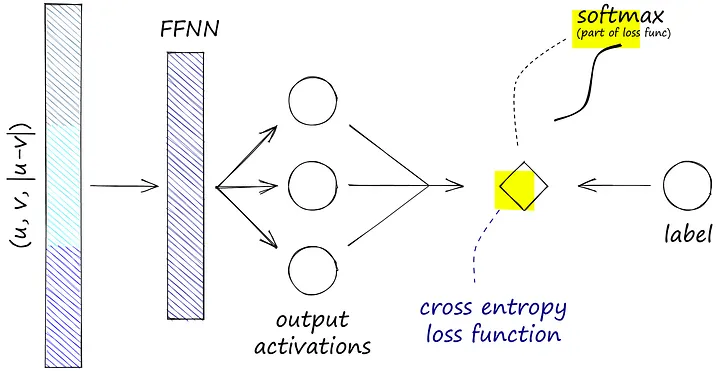
这三个输出分别对应我们的NLI相似度标签0、1和2。我们需要从FFNN计算softmax,这在交叉熵损失函数中完成。softmax和标签用于优化这个“softmax损失”。
这使得相似句子(标签0)的池化句子嵌入变得更加相似,不相似句子(标签2)的嵌入变得更加不同。
请记住,我们使用的是孪生BERT,而不是两个独立的BERT。这意味着我们不是使用两个独立的BERT模型,而是使用一个BERT依次处理句子A和句子B。
这意味着,当我们优化模型权重时,权重会朝着让模型在看到蕴涵标签时输出更相似的向量,在看到矛盾标签时输出更不相似向量的方向调整。
4. SBERT目标函数
通过使用这两个向量u和v,下面讨论优化不同目标的三种方法。
4.1. 分类
将三个向量u、v和|u-v|连接起来,乘以一个可训练的权重矩阵W,然后将乘法结果输入到softmax分类器中,该分类器会输出对应不同类别的句子的标准化概率。交叉熵损失函数用于更新模型的权重。

4.2. 回归
在此公式中,在获得向量u和v后,它们之间的相似性分数由选定的相似性度量直接计算。将预测的相似性分数与真实值进行比较,并使用均方误差(MSE)损失函数更新模型。

4.3. 三重损失
三元组目标引入了一个三元组损失,该损失是根据三个句子计算的,这三个句子通常被命名为锚点(anchor)、正样本(positive)和负样本(negative)。假设锚点句子和正样本句子非常相似,而锚点句子和负样本句子差异很大。在训练过程中,模型会评估(锚点,正样本)这一对与(锚点,负样本)这一对相比有多接近。

现在,让我们看看如何初始化和使用这些句子转换模型。
5. 动手句子转换器
开始使用句子转换器的最快、最简单的方法是通过SBERT的创建者开发的sentence-transformers库。我们可以使用pip进行安装:
我们将从原始的SBERT模型bert-base-nli-mean-tokens开始。首先,下载并初始化模型:
输出:
我们在这里看到的输出是SentenceTransformer对象,它包含三个组件:
- Transformer本身:在这里我们可以看到最大序列长度为128个标记,以及是否将输入转换为小写(在这种情况下,模型不会转换)。我们还可以看到模型类
BertModel。 - 池化操作:在这里我们可以看到我们正在生成一个768维的句子嵌入。我们使用均值池化方法来实现这一点。
一旦有了模型,使用encode方法就可以快速构建句子嵌入。
输出:
6. 选择哪种嵌入模型?
然而,我们很快就会发现,目前使用的大多数嵌入模型都属于Transformer类别。这些模型由不同的提供商提供,其中一些是开源的,另一些是专有的,每个模型都针对特定目标量身定制:
- 有些最适合编码任务。
- 其他的则是专为英语设计的。
- 也有一些嵌入模型在处理多语言数据集方面表现出色。
最简单的方法是利用现有的学术基准。不过,请务必记住,这些基准可能无法全面反映人工智能应用中检索系统在现实世界中的使用情况。
或者,你可以使用各种嵌入模型进行测试,并编制一份最终评估表,以确定最适合你特定用例的模型。我强烈建议在此过程中加入重排器,因为它可以显著提高检索器的性能,最终获得最佳结果。
为了简化你的决策过程,Hugging Face提供了出色的海量文本嵌入基准(MTEB)排行榜。这个资源提供了所有可用嵌入模型的全面信息,以及它们在各种指标上的相应得分:

结论
本文探讨了各种用于生成文本向量表示的嵌入模型,包括词袋模型(BoW)、TF-IDF、Word2Vec、GloVe、FastText、ELMO、BERT等等。深入研究了BERT的架构和预训练,介绍了用于高效生成句子嵌入的句子BERT(SBERT),并提供了一个使用sentence-transformers库的实践示例。结论部分强调了选择正确嵌入模型的挑战,并建议利用Hugging Face的海量文本嵌入基准(MTEB)排行榜等资源进行评估。
推荐阅读
1. DeepSeek-R1的顿悟时刻是如何出现的? 背后的数学原理
2. 微调 DeepSeek LLM:使用监督微调(SFT)与 Hugging Face 数据
3. 使用 DeepSeek-R1 等推理模型将 RAG 转换为 RAT
4. DeepSeek R1:了解GRPO和多阶段训练
5. 深度探索:DeepSeek-R1 如何从零开始训练
6. DeepSeek 发布 Janus Pro 7B 多模态模型,免费又强大!
- 感谢你赐予我前进的力量
-
 微信
微信 - 支付宝

