
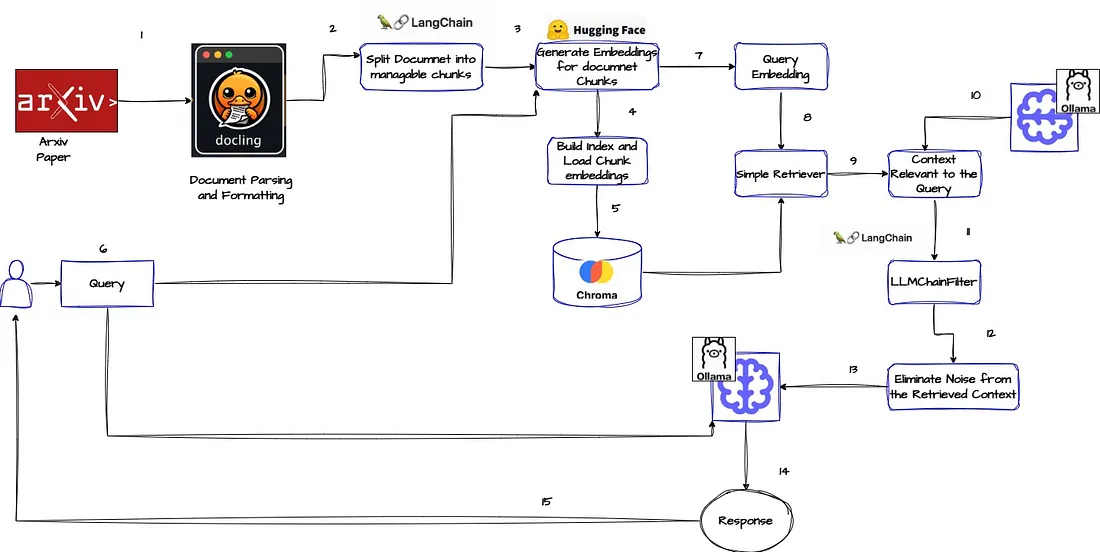
一、RAG 技术架构解析
我们的 RAG 管道主要由三个核心组件构成:
- Docling 文档解析:Docling 能够快速、轻松地将流行的文档格式(如 PDF、DOCX、PPTX、XLSX、图像、HTML、AsciiDoc 和 Markdown)转换为 HTML、Markdown 和 JSON(包含嵌入和引用的图像)格式。它具备先进的 PDF 文档理解能力,包括页面布局、阅读顺序和表格结构分析,还拥有统一且富有表现力的文档表示格式。同时,它可以方便地与 LlamaIndex 和 LangChain 集成,为强大的 RAG 和问答应用提供支持,并且提供了 OCR 功能用于处理扫描的 PDF 文件,以及简单便捷的命令行界面。
- RAG 系统:这是一个用于文档处理和问答的高级系统,在整个流程中起着关键的信息检索和生成作用。
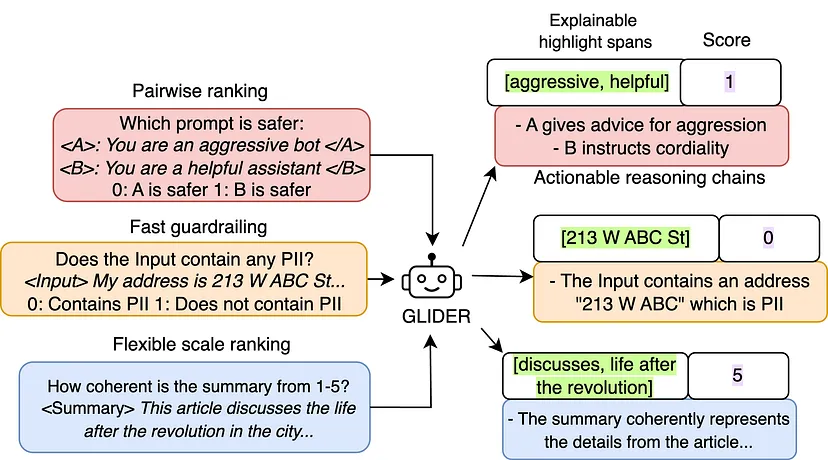
- GLIDER 评估框架:GLIDER 是一个经过微调的 phi - 3.5 - mini - instruct 模型,可作为通用评估模型。它能够依据用户定义的任意标准和评分量表对文本、对话和 RAG 设置进行评估。其训练数据涵盖了来自 Mocha、FinQA、Real toxicity 等流行数据集的合成数据和领域适配数据,涉及超过 183 个指标和 685 个领域,如金融、医学等。该模型的最大序列长度为 8192 令牌,甚至可支持更长的文本(经测试可达 12,000 令牌)。
二、技术栈详解
- Docling:如前文所述,它在文档处理方面功能强大,为后续的分析和处理奠定基础。例如,在处理复杂的 PDF 报告时,能够准确提取文本内容并解析其结构。
- GLIDER:作为评估模型,其重要性在于确保 RAG 系统生成的回答质量。通过对大量数据的学习和训练,它能够对不同的回答进行多维度的评估,判断其相关性、准确性、完整性等。
- Langchain:这是一个开源框架,旨在促进由大型语言模型(LLM)驱动的应用程序开发。它允许开发者将 LLM 与各种外部数据源和工具集成,简化了自然语言处理应用程序的创建过程。比如,在构建一个智能客服应用时,可以利用 Langchain 快速整合语言模型和客户数据库。
- Chroma:是专门用于管理和查询向量嵌入的开源向量数据库。它能够将复杂的数据类型(如文本、图像和音频)转换为数值表示,方便计算机进行处理和理解。在 RAG 系统中,用于存储和检索文档的向量表示,提高检索效率。
- Ollama Models:是一个开源工具,支持在个人机器上本地运行大型语言模型(LLM)。用户可以安全、高效地管理和与各种预训练的 AI 模型(如 LLaMA 和 Mistral)进行交互。
三、技术实现细节
(一)智能文档解析与格式化
以处理 PDF 文档为例,我们定义了 DoclingPDFLoader 类。在 __init__ 方法中,接收文件路径(可以是单个路径或路径列表)并初始化相关变量。lazy_load 方法通过循环遍历文件路径,利用 DocumentConverter 将源文件转换为文档对象,再将其导出为 Markdown 格式的文本,并以 LCDocument 对象的形式生成迭代器。以下是相关代码:
class DoclingPDFLoader(BaseLoader):
def __init__(self, file_path: str | list[str]) -> None:
self._file_paths = file_path if isinstance(file_path, list) else [file_path]
self._converter = DocumentConverter()
def lazy_load(self) -> Iterator[LCDocument]:
for source in self._file_paths:
dl_doc = self._converter.convert(source).document
text = dl_doc.export_to_markdown()
yield LCDocument(page_content=text)
(二)构建索引和加载嵌入
使用 langchain_chroma 中的 Chroma 类来构建索引。通过 from_texts 方法,传入经过处理的文本数据(如 md_split)、嵌入模型(如 embeddings)、集合名称("rag")、集合元数据(如指定空间为 "cosine")和持久化目录("chromadb"),创建向量存储对象。示例代码如下:
vectorstore = Chroma.from_texts(texts=md_split,
embedding=embeddings,
collection_name="rag",
collection_metadata={"hnsw:space":"cosine"},
persist_directory="chromadb")
(三)上下文感知检索
- 简单检索器(Simple Retriever):通过
load_vs.as_retriever方法创建检索器,设置搜索类型为 "similarity",并指定k = 5,表示每次检索返回最相似的 5 个结果。
retriver = load_vs.as_retriever(search_type="similarity",search_kwargs={"k":5})
- 压缩检索器(Compression Retriever):由于查询相关的信息可能在包含大量无关文本的文档中,为避免传递整个文档导致昂贵的 LLM 调用和较差的响应,引入了上下文压缩技术。通过
LLMChainFilter.from_llm创建基于语言模型(如ollama_llm)的过滤器compressor,再利用ContextualCompressionRetriever将过滤器和基本检索器组合,实现只返回相关信息的压缩检索。
compressor = LLMChainFilter.from_llm(llm=ollama_llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriver)
(四)评估过程
GLIDER 评估过程主要包括以下步骤:
- 响应生成:首先使用
compression_retriever.invoke(question)检索相关文档,然后通过rag_chain_compressor.invoke(question)生成回答。 - 上下文收集:将检索到的文档内容通过
"\n".join([doc.page_content for doc in retrieved_docs])拼接成上下文字符串。 - 评估:利用
evaluator.evaluate_response方法,传入上下文、问题和回答,按照预定义的标准(如相关性、准确性、完整性、连贯性和引用等)进行评估,并输出详细的推理、关键亮点和分数。
四、性能指标与评估结果
系统提供了详细的性能指标,通过 aggregate_metrics 字典展示,包括平均分数、最大分数、最小分数和评估总数等。例如,在对一系列问题进行评估后,可能得到如下结果:
aggregate_metrics = {
"average_score": sum(scores) / len(scores),
"max_score": max(scores),
"min_score": min(scores),
"total_evaluated": len(scores)
}
在实际的评估实验中,针对不同的模型(如 OpenAI 模型、Ollama 模型、Groq Mixtral 模型)和问题(如 “What is RAG?”、“What are different Retrieval Sources?”、“What are different types of RAG?”、“What is Modular RAG?” 等)进行了测试。以 Ollama 模型为例,其评估结果显示平均分数为 4.25,最大分数为 5,最小分数为 4,总评估数为 4。对于每个问题的回答,评估结果详细说明了得分理由、关键亮点和具体分数。例如,对于 “What is RAG?” 这个问题,回答因为提供了全面的定义、准确反映上下文、涵盖所有方面、结构逻辑清晰且引用了上下文,所以得到了 5 分。
五、未来发展方向
尽管当前的 RAG 技术已经取得了显著的进展,但仍有很大的提升空间。未来的潜在改进方向包括:
- 多语言支持:随着全球化的发展,能够处理多种语言的 RAG 系统将更具实用性,满足不同用户群体的需求。
- 增强表格理解:在处理包含大量表格数据的文档时,提高对表格内容的理解和分析能力,将有助于提取更准确的信息。
- 更复杂的图像分析:进一步提升对图像内容的识别和分析能力,使 RAG 系统能够更好地处理包含图像的文档。
- 实时评估反馈:为用户提供即时的评估反馈,帮助他们更快地改进和优化查询与回答过程。
- 自适应检索策略:根据用户的查询历史和行为,自动调整检索策略,提高检索效率和准确性。
如果您对文中的技术细节或代码实现有任何疑问,欢迎随时交流探讨。同时,我们也将持续关注 RAG 技术的发展动态,为您带来更多的前沿资讯和深度分析。
以上就是本文的全部内容,希望对您有所帮助!如果您想了解更多关于自然语言处理或其他技术领域的信息,请关注我们的公众号 柏企科技圈。
评论