
探索 Microsoft AutoGen 框架:AI 协作的新前沿
在众多的工具中,Microsoft 的 AutoGen 框架格外引人注目。它是一款强大的工具,专门用于创建和管理多Agent对话。通过这个框架,构建 AI 系统变得更加简便,这些系统能够利用Agent之间的交互,实现协作、推理,并解决各类复杂问题。
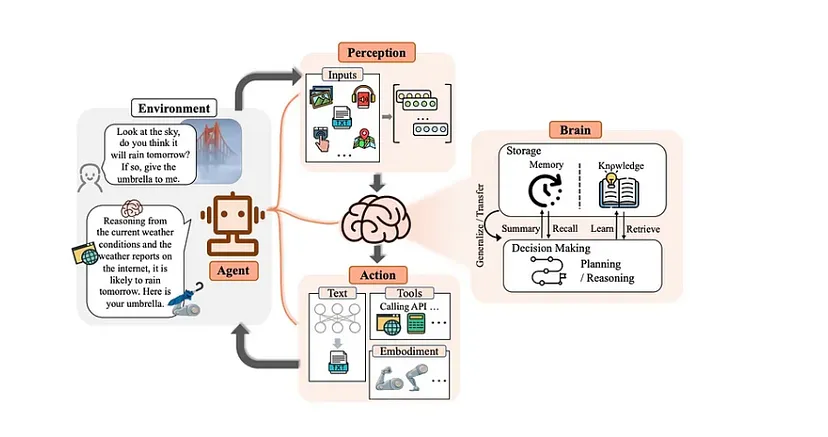
一、什么是Agent?
Agent是一种特殊的实体,它具有多种能力。它可以利用 GenAI 模型、工具、人工输入或者这些方式的组合,来发送和接收消息,并生成相应的响应。这种独特的抽象设计意义重大,它不仅能够让Agent对现实世界中的人员以及抽象的算法等实体进行模拟,还极大地简化了复杂工作流程的实施过程。
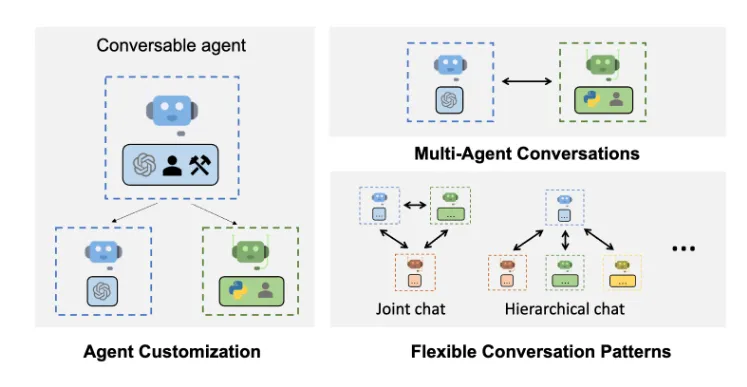
二、AutoGen 框架的亮点
AutoGen 由研究人员和工程师组成的社区共同开发。它融合了多Agent系统领域的最新研究成果,并在许多实际应用场景中发挥了重要作用。
这个框架具有可扩展和可组合的特性。这意味着开发者可以使用可自定义的组件对简单的Agent进行扩展,还能够将不同的Agent组合起来,形成更加强大的Agent工作流。同时,它的模块化设计使得其易于实施,为开发者提供了极大的便利。
三、AutoGen Agent的奥秘
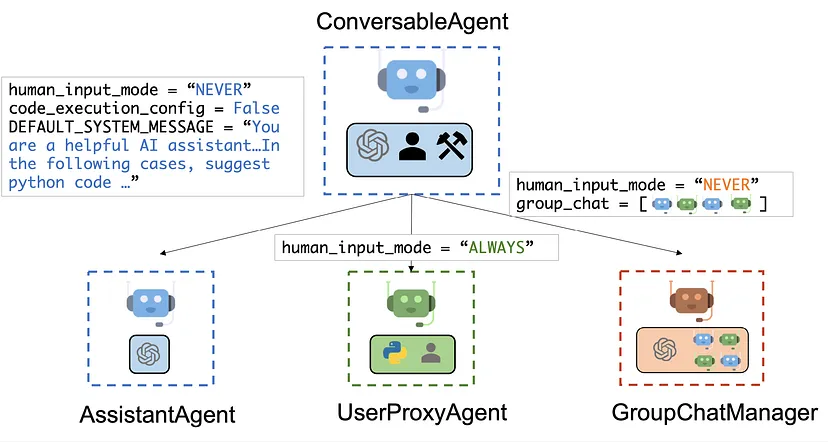
AutoGen 的核心是可交谈的Agent,它是具有基础功能的Agent,也是其他所有 AutoGen Agent的基类。这类Agent能够积极参与对话,高效处理信息,并执行各种任务。
AutoGen 提供了多种预定义的Agent类型,每种类型都针对特定的角色进行了精心设计。例如:
- AssistantAgent:这是一种通用的 AI 助手,能够很好地理解用户的查询,并给出准确的响应。
- UserProxyAgent:主要用于模拟用户行为,在测试和开发Agent交互的过程中发挥着关键作用。
- GroupChat:它可以将多个Agent进行分组,这些分组后的Agent会作为一个系统协同工作,共同完成特定的任务。
在 AutoGen 中,存在多种对话模式,这些模式为解决复杂问题和完成任务提供了有效的途径。常见的对话模式包括:
- Agent之间的一对一对话,这种模式简单直接,适用于一些简单的信息交流和任务处理。
- 多个Agent参与的群聊,通过群聊,Agent们可以集思广益,共同解决复杂问题。
- 分层对话,在这种模式下,Agent可以将任务委派给子Agent,实现任务的分层处理,提高工作效率。
四、AutoGen 的工作原理
AutoGen 通过对 AI Agent进行复杂的编排,有效地促进了多Agent对话和任务的执行。其工作流程主要包括以下几个关键环节:
(一)Agent初始化
在使用 AutoGen 时,首先要进行Agent的初始化操作。这需要创建所需Agent类型的实例,并根据具体的任务需求,使用特定的参数对其进行配置。例如:
from autogen import AssistantAgent, UserProxyAgent
assistant1 = AssistantAgent("assistant1", llm_config={"model": "gpt-4","api_key":"<YOUR API KEY>"})
assistant2 = AssistantAgent("assistant2", llm_config={"model": "gpt-4","api_key":"<YOUR API KEY>"})
(二)对话流程
完成Agent初始化后,AutoGen 会负责管理Agent之间的对话流。其典型的流程如下:
- 首先引入一个任务或查询,这是整个流程的起点。
- 相应的Agent会对输入的任务或查询进行处理,利用自身的能力和知识,分析问题并寻找解决方案。
- Agent生成响应,并将其传递给下一个Agent或者直接返回给用户。这个过程中,Agent会根据任务的要求和自身的判断,选择合适的方式进行响应。
- 上述循环会持续进行,直到任务顺利完成或者满足预先设定的终止条件。
对于更为复杂的任务流程,我们可以将多个Agent合并到一个名为 GroupChat 的组中,然后借助 Group Manager 来管理对话。每个小组和小组管理员都有其特定的任务分工,确保整个系统的高效运行。
(三)任务执行
随着对话的逐步推进,Agent可能需要执行一些特定的任务。AutoGen 提供了多种任务执行方式,以满足不同的需求:
- 自然语言处理:Agent能够解释并生成多种语言的类人文本,这使得它在语言相关的任务中表现出色,如文本生成、翻译等。
- 代码执行:Agent可以自动创建、编写、运行和调试各种编程语言的代码。这对于软件开发和自动化任务来说,是一个非常强大的功能。例如,在开发一个小型应用程序时,Agent可以根据需求生成相应的代码,并进行调试和优化。
- 外部 API 调用:Agent可以与外部服务进行交互,获取或处理数据。比如,在进行数据分析时,Agent可以调用数据库的 API,获取所需的数据,并进行进一步的分析和处理。
- 搜索 Web:Agent能够自动搜索网络,如 Wikipedia 等,提取特定查询的信息。当需要了解某个领域的知识时,Agent可以快速在网络上搜索相关信息,并进行整理和总结。
(四)错误处理和交互
AutoGen 具备强大的错误处理能力。当Agent在执行任务过程中遇到错误时,它通常能够自主地进行诊断,并尝试修复问题。这种机制形成了一个持续改进和解决问题的循环,不断提升系统的稳定性和可靠性。
(五)会话终止
AutoGen 中的会话终止是基于预定义的条件来实现的。这些条件包括任务完成、达到预先设定的回合数、接收到显式的终止命令或者错误阈值等。这种灵活的终止条件设置,使得系统能够根据不同的任务和场景,实现快速和有针对性的交互。
五、AutoGen 的应用案例
AutoGen 在多个领域都有着广泛的应用,展现出了强大的功能和潜力。
(一)解决复杂问题
AutoGen 擅长通过多Agent协作的方式,对复杂问题进行分解和求解。在科学研究领域,它可以用于分析大量的数据,帮助研究人员制定合理的假设,并设计科学的实验方案。例如,在天文学研究中,面对海量的天体观测数据,AutoGen 可以协助研究人员筛选出有价值的数据,并进行分析和建模,从而推动科学研究的进展。
(二)代码生成和调试
它能够跨多种编程语言生成、执行和调试代码。对于软件开发人员来说,这是一个非常实用的工具。在开发一个新的软件项目时,开发人员可以利用 AutoGen 快速生成一些基础的代码框架,并进行调试和优化,大大提高开发效率。
(三)自动广告系统
AutoGen 框架非常适合多Agent自动化广告管理。它可以跟踪客户的评论和广告点击情况,对定向广告进行自动 AB 测试,并利用 Gemini 和 Stable diffusion 等 GenAI 模型,生成针对特定客户的广告内容。通过这种方式,广告投放的效果可以得到显著提升,为企业带来更好的营销效果。
(四)教育辅导
AutoGen 可以创建交互式的辅导体验,让不同的Agent分别扮演教师、学生和评估员等角色。例如,在一个数学辅导场景中:
from autogen import AssistantAgent, UserProxyAgent
teacher = AssistantAgent("Teacher", llm_config={"model": "gpt-4","api_key":"<YOUR API KEY>"})
student = UserProxyAgent("Student")
evaluator = AssistantAgent("Evaluator", llm_config={"model": "gpt-4","api_key":"<YOUR API KEY>"})
def tutoring_session():
student.initiate_chat(teacher, message="I need help understanding quadratic equations.")
# 教师解释概念
student.send(evaluator, "Did I understand correctly? A quadratic equation is ax^2 + bx + c = 0")
# 评估员评估理解情况并提供反馈
teacher.send(student, "Let's solve this equation: x^2 - 5x + 6 = 0")
# 学生尝试解答
evaluator.send(teacher, "Assess the student's solution and provide guidance if needed.")
tutoring_session()
通过这种方式,学生可以获得更加个性化和有效的辅导,提高学习效果。
六、在项目中实现 AutoGen
下面我们将通过一个具体的项目,展示如何在实际中使用 AutoGen。在这个项目中,我们将利用 AutoGen Agent从网络上下载一个数据集,并尝试使用 LLM 对其进行分析。
(一)环境设置
$ conda create -n autogen python=3.11
$ conda activate autogen
pip install numpy pandas matplolib seaborn python-dotenv jupyterlab
pip pyautogen
完成上述安装后,打开 Vscode,并创建一个 Jupyter 笔记本,以此启动项目。
(二)加载库
import os
import autogen
from autogen.coding import LocalCommandLineCodeExecutor
from autogen import ConversableAgent
from dotenv import load_dotenv
接下来,需要从相应的站点收集生成模型的 API 密钥,并将其放入项目根目录下的.env 文件中。以下代码可以将 API 密钥加载到系统中:
load_dotenv()
google_api_key = os.getenv("GOOGLE_API_KEY")
open_api_key = os.getenv("OPENAI_API_KEY")
os.environ["GOOGLE_API_KEY"] = google_api_key.strip('"')
os.environ["OPENAI_API_KEY"] = open_api_key.strip('"')
seed = 42
对于 GeminiAI 和 OpenAI,我们可以根据实际情况进行配置。例如,如果使用 GeminiAI 免费版本测试代码,可以将 gemini safety 设置为 NONE:
safety_settings = [
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"},
]
(三)配置 LLM
根据使用的模型不同,需要进行相应的配置。例如,将 LLM 配置为 Gemini-1.5-flash:
llm_config = {
"config_list": [
"model": "gemini-1.5-flash",
"api_key": os.environ["GOOGLE_API_KEY"],
"api_type": "google",
"safety_settings": safety_settings,
]
}
或者配置为 OpenAI:
llm_config = {
"config_list": [{"model": "gpt-4", "api_key": os.getenv("OPENAI_API_KEY")}]
}
(四)定义编码任务
coding_task = [
"""download data from https://raw.githubusercontent.com/vega/vega-datasets/main/data/penguins.json""",
""" find desccriptive statistics of the dataset, plot a chart of their relation between spices and beak length and save the plot to beak_length_depth.png """,
"""Develope a short report using the data from the dataset, save it to a file named penguin_report.md."""
]
(五)设计 Assistant Agent
在这个项目中,我们将使用四个助手,分别是 User Proxy、Coder、Writer 和 Critic。
- User Proxy Agent:
它是 AutoGen User Agent,是 ConversableAgent 的子类。其 human_input_mode 原本是 ALWAYS,意味着它会作为人工Agent工作,但在这里我们将其设置为 NEVER,使其能够自主工作。
user_proxy = autogen.UserProxyAgent(
name="User_proxy",
system_message="A human admin.",
code_execution_config={
"last_n_messages": 3,
"work_dir": "groupchat",
"use_docker": False
},
human_input_mode="NEVER"
)
- Code 和 Writer Agent:
这两个Agent利用 AutoGen Assistant Agent 构建,它是 Conversable Agent 的子类,旨在解决 LLM 的任务,human_input_mode 为 NEVER。我们可以为助理Agent设置系统消息提示。
coder = autogen.AssistantAgent(
name="Coder",
llm_config=llm_config
)
writer = autogen.AssistantAgent(
name="writer",
llm_config=llm_config,
system_message="""
You are a professional report writer, known for
your insightful and engaging report for clients.
You transform complex concepts into compelling narratives.
Reply "TERMINATE" in the end when everything is done.
"""
)
- Critic Agent:
它是一个助理Agent,主要负责评估编码Agent创建的代码质量,并提出改进建议。
system_message="""Critic. You are a helpful assistant highly skilled in
evaluating the quality of a given visualization code by providing a score
from 1 (bad) - 10 (good) while providing clear rationale. YOU MUST CONSIDER
VISUALIZATION BEST PRACTICES for each evaluation. Specifically, you can
carefully evaluate the code across the following dimensions
- bugs (bugs): are there bugs, logic errors, syntax error or typos? Are
there any reasons why the code may fail to compile? How should it be fixed?
If ANY bug exists, the bug score MUST be less than 5.
- Data transformation (transformation): Is the data transformed
appropriately for the visualization type? E.g., is the dataset appropriated
filtered, aggregated, or grouped if needed? If a date field is used, is the
date field first converted to a date object etc?
- Goal compliance (compliance): how well the code meets the specified
visualization goals?
- Visualization type (type): CONSIDERING BEST PRACTICES, is the
visualization type appropriate for the data and intent? Is there a
visualization type that would be more effective in conveying insights?
If a different visualization type is more appropriate, the score MUST
BE LESS THAN 5.
- Data encoding (encoding): Is the data encoded appropriately for the
visualization type?
- aesthetics (aesthetics): Are the aesthetics of the visualization
appropriate for the visualization type and the data?
YOU MUST PROVIDE A SCORE for each of the above dimensions.
{bugs: 0, transformation: 0, compliance: 0, type: 0, encoding: 0,
aesthetics: 0}
Do not suggest code.
Finally, based on the critique above, suggest a concrete list of actions
that the coder should take to improve the code.
"""
critic = autogen.AssistantAgent(
name="Critic",
system_message = system_message,
llm_config=llm_config
)
(六)群聊和管理器创建
在 AutoGen 中,我们使用 GroupChat 功能将多个Agent组合在一起,以执行特定任务,并使用 GroupChatManager 控制 GroupChat 行为。
groupchat_coder = autogen.GroupChat(
agents=[user_proxy, coder, critic], messages=[], max_round=10
)
groupchat_writer = autogen.GroupChat(
agents=[user_proxy, writer, critic], messages=[], max_round=10
)
manager_1 = autogen.GroupChatManager(
groupchat=groupchat_coder,
llm_config=llm_config,
is_termination_msg=lambda x: x.get("content", "").find("TERMINATE") >= 0,
code_execution_config={
"last_n_messages": 1,
"work_dir": "groupchat",
"use_docker": False
}
)
manager_2 = autogen.GroupChatManager(
groupchat=groupchat_writer,
name="Writing_manager",
llm_config=llm_config,
is_termination_msg=lambda x: x.get("content", "").find("TERMINATE") >= 0,
code_execution_config={
"last_n_messages": 1,
"work_dir": "groupchat",
"use_docker": False
}
)
最后,创建一个用户Agent来启动聊天过程并检测终止命令:
user = autogen.UserProxyAgent(
name="User",
human_input_mode="NEVER",
is_termination_msg=lambda x: x.get("content", "").find("TERMINATE") >= 0,
code_execution_config={
"last_n_messages": 1,
"work_dir": "tasks",
"use_docker": False
}
)
user.initiate_chats(
{"recipient": coder, "message": coding_task[0], "summary_method": "last_msg"},
{"recipient": manager_1, "message": coding_task[1], "summary_method": "last_msg"},
{"recipient": manager_2, "message": coding_task[2]}
)
在这个项目中,Agent会按照以下步骤工作:首先下载企鹅数据集,然后由 coder Agent创建代码,critic Agent对代码进行评估和建议改进,接着 coder Agent根据建议重新运行代码进行优化,之后 writer Agent利用处理后的数据编写报告,critic Agent同样会对报告内容进行评估和指导,最终完成整个任务流程。
推荐阅读
3. AI Agent 架构新变革:构建自己的 Plan-and-Execute Agent
5. 探秘 GraphRAG:知识图谱赋能的RAG技术新突破

后续我们会持续带来更多相关技术的深度解析和实践案例,敬请关注公众号 柏企科技圈
评论